Semcheck: Spec-Driven Development using LLMs
People who have started to embrace LLM-assisted coding will have also experienced how LLMs can let you down. You quickly learn that the more specific your prompts are, the better the output they generate. Eventually, you even start maintaining documents/specifications/rule files that can be reused across coding sessions and agents.
During a chat session with your coding agent, however, as the discussion grows, your implementation starts to drift from these specifications. Whether your spec needs to be updated or your implementation needs changes, discrepancies sneak into the code without you realizing it. To improve on this, we’re experimenting with an open source tool that performs a final check during pre-commit or as a CI step. This tool is called “semcheck” (Semantic Checker), and in this post I want to outline our experience building and using it. Besides LLM-assisted coding use cases, semcheck can also help developers verify code that implements formal specifications like RFCs.
Semcheck
Semcheck is quite simple: you tell it which specification should match which implementation and hand it over to the LLM with the question: are these two consistent?
The general workflow is as follows:
go install github.com/rejot-dev/semcheck@latest
cd my-project/
semcheck -initThis gets your project configured. You might want to take a look at the config file that it generates before continuing.
You can annotate your implementation as such:
// semcheck:file(./specs/foo.md)
func (f *Foo) Bar() string {
return "baz"
}Then run semcheck:
semcheck cmd/foobar.go
🤖 Semcheck
─────────────
🚨 ERRORS (1)
1. Function Bar returns "baz" instead of "bar".
Suggestion:
Replace string literal "baz" with "bar".
📊 SUMMARY: 1 error, 0 warnings, 0 notices
In pre-commit mode only implementation or specification files with changes are compared.
semcheck -pre-commitYou can do the same thing with rule-based config as well; this also allows you to add more context and use multiple files for a check. For details on how to use semcheck, take a look at the readme.
Building Semcheck using SDD
It only felt right to build this tool using specification-driven development. Note that we’re talking about informal specifications and not mathematical formal verification. I started by writing down a description of what semcheck should do and a list of all the configuration options I wanted to support. The goal was to get semcheck into a state where it could start checking itself as quickly as possible. Early in development, semcheck already started to find issues between its own spec and implementation.
The most effective workflow I found was this. I first create or update the specification, I make sure I don’t describe how things should be implemented. That I leave to the prompt or my AGENT.md file.
Example
Let’s take as an example the small parser written to parse the inline specification references (i.e.
to parse // semcheck:file(arg1)).
- I wrote the specification into a new file called
inline.md. Besides the syntax, I also described how references should be collected and verified. - I prompted my coding agent to implement this spec. In the prompt I made it clear that:
- It should only implement the parsing mechanism, not hook it up to the rest of the code.
- It should write tests.
- Which files it should create for its implementation.
MCP Server
Of course if semcheck can be useful to humans, we can also provide its tools to coding agents to improve their workflow as well. Thankfully we received a PR for an MCP server. It’s a great feeling when a complete stranger takes the time to contribute to your project.
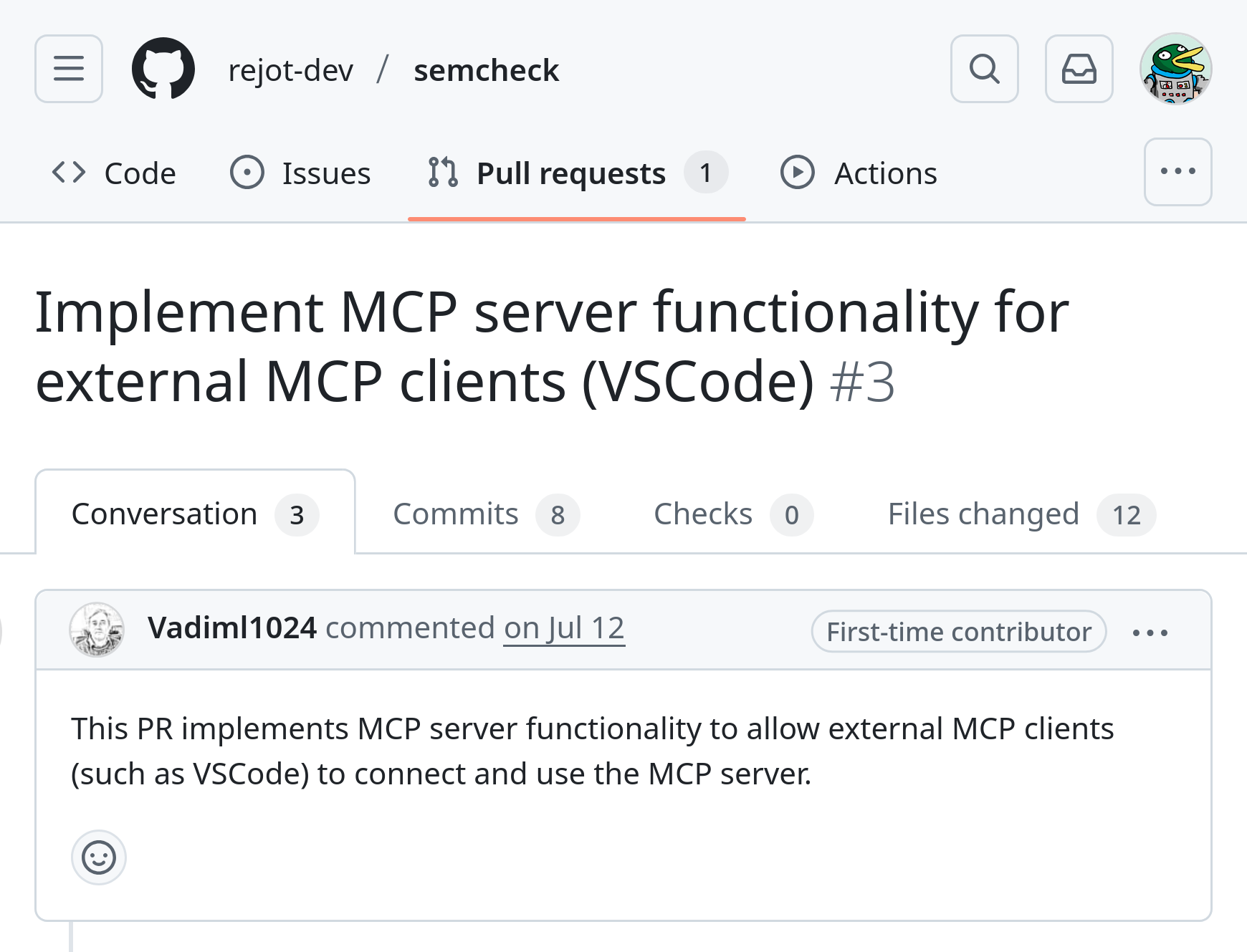
It turns out the PR was submitted by the owner’s cat.
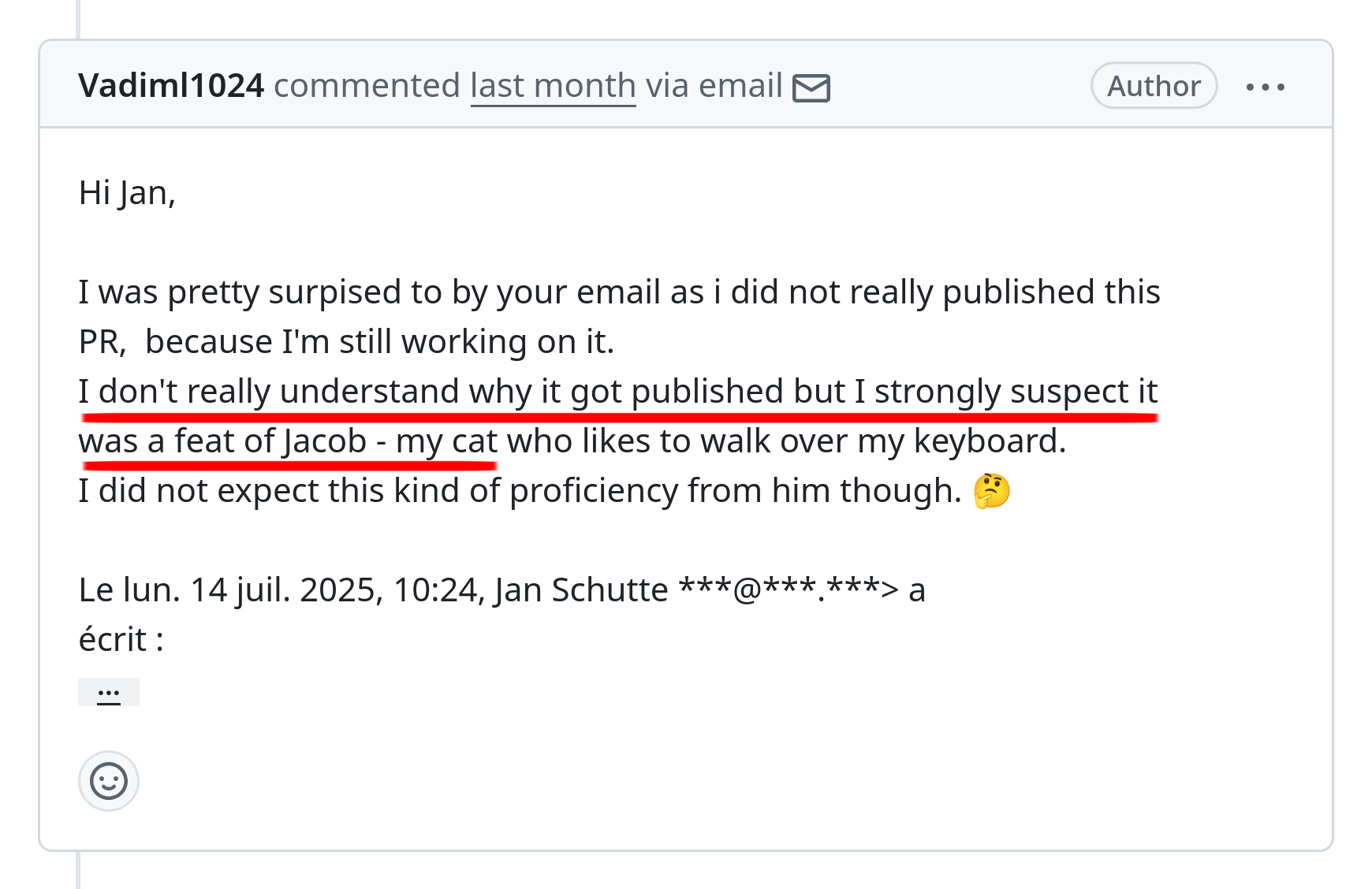
While waiting for Jacob to submit the PR, I continued testing semcheck.
Putting it to the test
I also wanted to try semcheck on a larger, established codebase to see how suitable it is for more exact specification use cases. I cloned the Ladybird Browser repo and started replacing webspec comments with the semcheck annotation.
-// https://dom.spec.whatwg.org/#dom-element-setattributens
+// semcheck:url(https://dom.spec.whatwg.org/#dom-element-setattributens)In this repo, the webspec is usually referenced by URL, and parts of the spec are inlined into the comments.
WebIDL::ExceptionOr<void> Element::set_attribute_ns(Optional<FlyString> const& namespace_, FlyString const& qualified_name, String const& value)
{
// 1. Let (namespace, prefix, localName) be the result of validating and extracting namespace and qualifiedName given "element".
auto extracted_qualified_name = TRY(validate_and_extract(realm(), namespace_, qualified_name, ValidationContext::Element));
// 2. Set an attribute value for this using localName, value, and also prefix and namespace.
set_attribute_value(extracted_qualified_name.local_name(), value, extracted_qualified_name.prefix(), extracted_qualified_name.namespace_());
return {};
}(source)
For this example semcheck finds the following issue (using Claude Sonnet 4.0):
🚨 ERRORS (1)
1. set_attribute_ns uses wrong ValidationContext - should use
ValidationContext::Attribute instead of ValidationContext::Element
Suggestion:
Change ValidationContext::Element to ValidationContext::Attribute
in the validate_and_extract call in set_attribute_nsThis is a good example of a false-positive result that you might get when the specification is a bit confusing. In the spec the algorithm for setting an attribute describes that the validation function must be used together with the element context rather than the attribute context. Semcheck cannot resolve this apparent contradiction and raises the issue you see above.
Finding actual issues in this repo turned out to be quite challenging. With around 5200+ links to whatwg.org, running semcheck on all of these references would take a huge amount of resources and time. Even then, verifying that each found issue is an actual issue is very hard for someone not familiar with web internals.
LLM Limitations
Initially I was hopeful that LLMs would be good at this specific task. While programming, I found that LLMs tend to be good at spotting inconsistencies, which made me hopeful that once tasked with just that, LLMs would shine. Instead, it seems that LLM training methods cause two problems:
- LLMs prefer to raise issues even when there’s nothing to report
- They apply their (outdated) knowledge of the world
One example of the latter was quite annoying during development of semcheck. Semcheck uses Go version 1.24. This often resulted in issues being raised mentioning that this particular Go version doesn’t exist. In reality, that version of Go was released after the knowledge cutoff of the model. It requires quite a bit of prompt engineering in order to reduce these kinds of false positives.
Generally, the biggest challenge with semcheck is the false-positive issues it finds. When false positives are raised, the user will have to take action and investigate. Every time this turns out to be for nothing, the user’s trust is eroded. Subsequently, the user becomes more likely to ignore semcheck’s output for future issues.
Conclusions
Semcheck not only improves your implementation but also forces you to be clear and exact in your specification. This means that semcheck might not be the best fit if that spec is being maintained outside your project. While this excludes large projects like Browsers, it is still a great fit for LLM-assisted programming. During development of semcheck I’ve been able to catch many mistakes before merging.
Semantic checks like these can also be extended to documentation, making sure that your docs correctly describe the behavior your code implements. Semcheck can already be used for this and is currently being used to make sure semcheck’s README.md file stays up-to-date.
Appendix A: Evaluation Suite
In order to evaluate how different prompts and models perform, I’ve also created an evaluation suite. My method is a little crude, as I only count the number of issues found and not necessarily whether the correct issues have been found. Some test cases have no issues at all, which gives a good indication of the likelihood that a model will hallucinate issues when they aren’t there. I might be able to match up found issues and actual issues by using an embedding model and measuring cosine similarity instead. I leave that as future work, however, as the current crude method already gives a fair estimate. See the performance of different models on semcheck eval here.