Reliable Webhook Delivery on Cloudflare Workflows
An in-order webhook delivery system on Cloudflare Workflows
Reliable Webhook Delivery on Cloudflare Workflows
Cloudflare is a decent choice for hosting apps if you don’t want to deal with the complexity of setting up your own infrastructure, and can stomach the vendor lock-in. They’ve built an extensive ecosystem around their Worker platform: D1 for the database, Durable Objects for distributed state, Workflows for execution, R2 for storage, KV for caching, and even Queues.
I’d praise the platform for its simplicity (certainly when compared with traditional cloud providers). As always, keeping abstractions simple means making trade-offs. To evaluate these trade-offs I decided to build a small SaaS app with a webhook delivery system at its core.
Webhook delivery systems seem straightforward until you need ordering. This one requirement increases the complexity of the system significantly, which makes it an interesting case for evaluating an infrastructure platform.
The Requirements That Matter
Let’s be clear about what we’re building. Our webhook delivery system needs:
- Guaranteed at-least-once delivery
- Exponential backoff with retries
- Observable failure states (for admins and customers)
- Simple endpoint configuration
And the key requirement: strict ordering. Every event must be delivered in the exact sequence they occurred. Not all webhook systems guarantee this, but ours will.
Non-Cloudflare System Design
When designing (complex) systems, I find it easiest to first sketch out an approach based on simple
building blocks like traditional (relational) database systems. At the very least, we’d need a table
to track the customer-configured webhook endpoints. For the actual processing of the deliveries, I’d
go for the outbox pattern. A webhook_outbox table would contain pending deliveries. A tryAfter
column would be used to decide if a pending delivery should be retrieved. When delivery fails, the
row would be reinserted with exponential backoff based on attempt count. A background process would
continuously poll the outbox table and deliver the webhooks.
An alternative approach would be using a message queue system. If the queue supports sharding on a per-endpoint basis, even implementing full ordering would be relatively straightforward. This queue-based approach would still require the outbox pattern to guarantee at-least-once delivery. Presumably, we’d also like to atomically update the entity and insert the delivery into the outbox.
Cloudflare Workflows
Cloudflare describes Workflows as a “durable execution engine” that can “automatically retry,
persist state, and run for minutes, hours, days, or weeks.” The relatively small API surface is
comprised of three main methods: do, sleep, and waitForEvent. The elegance of Workflows lies
in the fact that normal control flow can be used to create complex workflows.
My first design made good use of this fact:
override async run(event: WorkflowEvent<Params>, step: WorkflowStep) {
const { endpoint } = event.payload;
while (true) {
const payload = await step.waitForEvent('Wait for webhook payload', {
type: 'webhook-payload',
timeout: '5 minutes',
});
await step.do(`Deliver webhook ${payload.id}`, async () => {
await sendWebhook(endpoint, payload);
});
}
}One workflow per endpoint, running forever, processing events as they arrive. Sounds pretty elegant.
Except Workflows aren’t designed for infinite loops. They have a hard limit of 1,024 steps. This constraint forced me toward a different architecture.
The Design That Actually Works
Since we can’t have infinite-running workflows, we need one workflow per delivery. But with strict ordering requirements, this creates a new challenge: concurrent workflows could complete out of order.
The solution is a distributed lock. Since we’re already using Durable Objects to store tenant-specific information, we can reuse this for the lock:
override async run(event: WorkflowEvent<Params>, step: WorkflowStep) {
const { instanceId } = event;
const lockStatus = await step.do("Acquire delivery lock", async () => {
const { activeInstanceId } = await durableObject.lockWebhookDeliveryProcessor(
webhookEndpointId,
instanceId,
);
if (activeInstanceId !== null && activeInstanceId !== instanceId) {
return "lock-not-acquired";
}
return "lock-acquired";
});
if (lockStatus === "lock-not-acquired") {
return;
}
// Deliver webhooks...
await step.do("Release lock and check pending", async () => {
await durableObject.unlockWebhookDeliveryProcessor({
webhookEndpointId,
instanceId,
maxDeliveredWebhookUlid,
});
});
}This implementation uses simple control flow to exit early when a lock is not acquired. The workflow’s durable execution means that the lock will always be released even if something fails. No orphaned locks, no complex timeout logic.
The High-Water Mark
To make everything work, we track a high-water mark. This is the maximum webhook ID that has been generated so far. We make sure this ID is naturally sortable and strictly monotonic. This is trivial to achieve in Durable Objects’ single-threaded environment. The high-water mark is used to check if new events arrived while we were actively delivering in a workflow. This check is done while unlocking the mutex. If the webhook ID that was just delivered is lower than the high-water mark, we trigger another workflow. Simple, elegant, and race-condition-free.
The actual delivery becomes straightforward:
try {
await step.do("Deliver webhook", async () => {
const response = await fetch(endpoint.url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"X-Webhook-Signature": generateSignature(endpoint, payload),
},
body: JSON.stringify(payload),
});
if (!response.ok) {
await markDeliveryAsPendingRetry(delivery);
throw new Error(`Delivery failed: ${response.status}`);
}
});
} catch (error) {
// After all retries are exhausted
await disableEndpointAndNotifyCustomer(endpoint);
}The platform handles exponential backoff. We just throw errors and let Cloudflare do the heavy lifting.
Observability
When vendor-locking yourself into a platform, you might as well reap the benefits. With Cloudflare Workflows, we get observability for free. Each workflow instance appears in Cloudflare’s dashboard with:
- Current step and status
- Retry attempts and timing
- Complete request/response payloads
- Failure reasons and stack traces
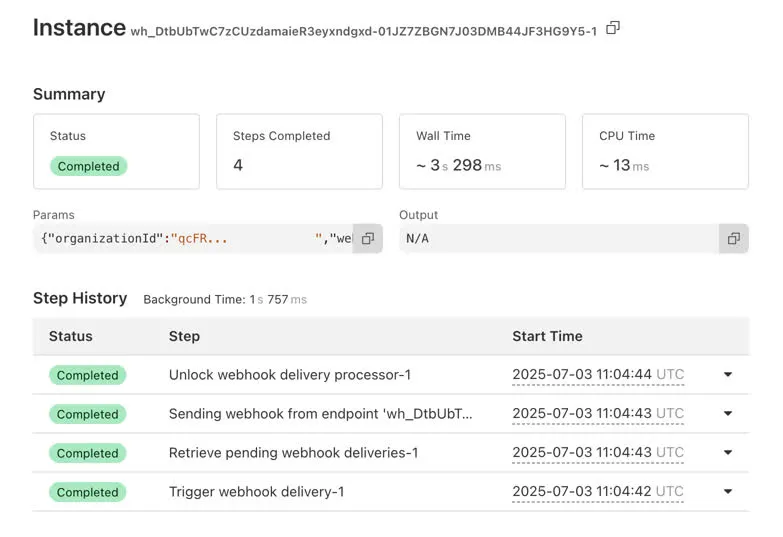
This eliminates the need for custom logging infrastructure or complex debugging workflows. When investigating delivery issues, administrators have access to complete execution traces that detail exactly what happened, when, and why.
What About Cloudflare Queues?
A big question remains: why not use Cloudflare Queues? Queues initially seem like a great fit for this use case, until you dig into the ordering requirement.
Cloudflare Queues don’t support partitions or sharding. To maintain order, you’d need a single consumer processing messages sequentially, creating a bottleneck. You could work around this by tracking endpoint state (blocked/available) in Durable Objects or KV, but now you’re building a distributed state machine on top of a queue system.
In the future, when Cloudflare Queues support partitions (they’ve hinted at this on their Discord), this implementation could be a lot less complex.
Conclusion
This design carries significant complexity, particularly when you consider the implementation details I’ve glossed over in this write-up. The distributed locking mechanism, error handling edge cases, and state management between Durable Objects and Workflows all require careful consideration.
The simplicity of Cloudflare’s platform proves to be a double-edged sword. While it’s easy to get started, certain requirements force you down unexpected implementation paths.
The real value of a platform like Cloudflare isn’t just in the core primitives, but in everything you get for free around them. Building comprehensive observability for a webhook delivery system on traditional infrastructure would be serious work. If you can stomach the vendor lock-in and the constraints of Cloudflare’s simplicity work for you, it’s a great choice.